
ข้อมูลทางเทคนิคที่ทำให้โฆษณาเทาถูกปฏิเสธ/ถูกลบ หรือโดนแบนซ้ำ ๆ และแนวทางแก้ไข


การที่บัญชีโฆษณาบน Facebook (Meta Ads) ถูกระงับหรือไม่ผ่านการอนุมัติในทันที มักไม่ใช่เพียงเพราะ “คอนเทนต์ผิดนโยบาย” เท่านั้น แต่เกี่ยวข้องกับ โครงสร้างทางเทคนิคของการตรวจสอบความเสี่ยง ซึ่ง Facebook ใช้ระบบอัลกอริทึมขั้นสูง, machine learning, และ heuristics ในการวิเคราะห์พฤติกรรมการใช้งาน
บทความนี้จะอธิบาย ปัจจัยหลัก 4 ประการ ที่นำไปสู่การถูกระงับโฆษณา พร้อมทั้ง แนวทางแก้ไข (Mitigation Strategies) เพื่อให้นักการตลาดสามารถลดความเสี่ยงและเพิ่มความน่าเชื่อถือของบัญชีโฆษณา
ปัจจัยที่นำไปสู่การถูกระงับโฆษณา
1. การใช้บัญชีโฆษณาเดิม (Account Reputation)
- Facebook มีระบบ account reputation score ที่สะท้อนประวัติการใช้งานของบัญชี เช่น อัตราโฆษณาที่ถูกปฏิเสธ, การละเมิดนโยบาย, และพฤติกรรมทางการเงิน
- หากบัญชีถูก flagged การใช้งานบัญชีเดิม แม้จะเปลี่ยนคอนเทนต์แล้ว ก็ยังคงอยู่ใน risk category เดิม
- ระบบ machine learning จะทำ predictive risk analysis โดยอิงจากข้อมูลเชิงสถิติ

สรุปเชิงเทคนิค: การใช้บัญชีโฆษณาเดิมเทียบได้กับการส่งข้อมูลเข้าสู่ระบบที่มี “negative prior probability” ทำให้โฆษณาถูกตรวจสอบเข้มงวดมากกว่าปกติ
2. IP Address และเครือข่าย (Network Fingerprinting)
- IP Address เป็นตัวชี้วัดสำคัญในการเชื่อมโยงผู้ใช้หลายบัญชี
- หาก IP เคยถูกใช้กับบัญชีที่ถูกปิด ระบบจะใช้เทคนิค IP reputation scoring เพื่อตัดสินความน่าเชื่อถือ
- Facebook อาจอ้างอิงข้อมูลจาก threat intelligence feed ภายนอกเพื่อระบุ IP ที่มีพฤติกรรมผิดปกติ เช่น VPN, หรือ datacenter IP

สรุปเชิงเทคนิค: IP Address ถูกใช้ในขั้นตอน risk clustering เพื่อระบุความเชื่อมโยงระหว่างบัญชีและพฤติกรรม
3. User-Agent และอุปกรณ์ (Device Fingerprinting)
- User-Agent ระบุข้อมูลเบราว์เซอร์และระบบปฏิบัติการ การใช้ค่าเดิมซ้ำ ๆ หรือค่าที่ผิดปกติอาจถูกมองว่าเป็น automation tool
- Meta ใช้ device fingerprinting โดยผนวกข้อมูล User-Agent, Canvas fingerprint, timezone, language setting และ hardware characteristics
- หากอุปกรณ์เคยเชื่อมกับบัญชีที่ถูกแบน บัญชีใหม่ที่ใช้อุปกรณ์นั้นมีโอกาสถูก flagged
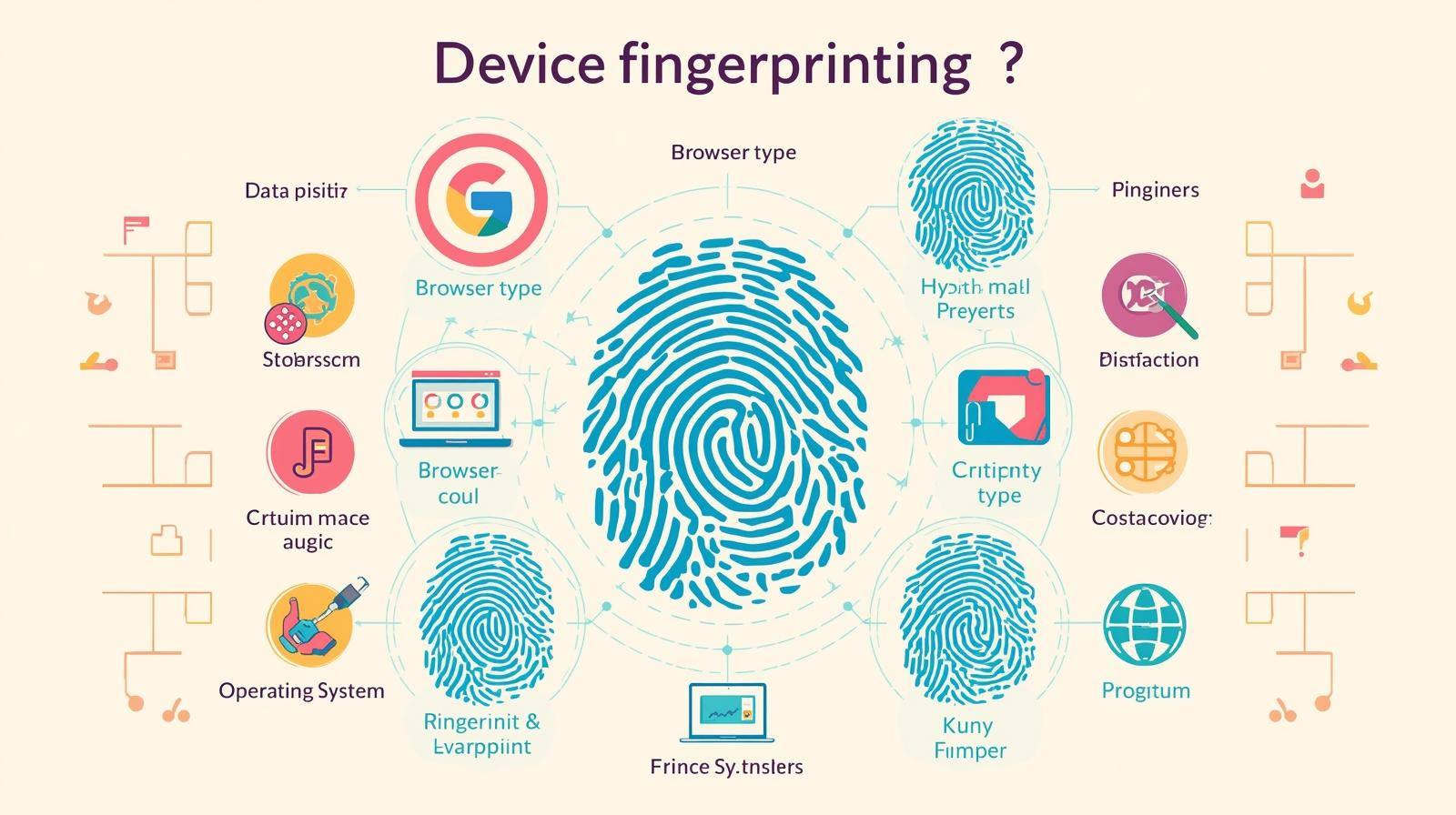
สรุปเชิงเทคนิค: User-Agent เป็นองค์ประกอบของ multi-dimensional fingerprint ที่ระบบ ML ใช้เพื่อหาความสัมพันธ์เชิงพฤติกรรม
4. ความคล้ายคลึงของสื่อโฆษณา (Content Similarity Detection)
- Meta ใช้ computer vision และ text similarity algorithms (เช่น cosine similarity, embedding models) เพื่อตรวจสอบความคล้ายคลึงของสื่อโฆษณา
- ภาพหรือวิดีโอที่มีองค์ประกอบคล้ายกับโฆษณาที่เคยถูกปฏิเสธจะถูกตรวจสอบเข้มงวด
- การใช้สื่อซ้ำหรือดัดแปลงเพียงเล็กน้อยอาจถูกระบุว่าเป็น evasion attempt
สรุปเชิงเทคนิค: การตรวจสอบใช้ทั้ง hashing และ deep learning models ไม่ได้พึ่งพาเพียง metadata
แนวทางแก้ไขและลดความเสี่ยง (Mitigation Strategies)
1. การจัดการบัญชีโฆษณา (Account Hygiene)
- สร้างบัญชีใหม่ภายใต้ Business Manager ที่ผ่านการยืนยันตัวตน (Business Verification) หรือบัญชี Agency ที่ผ่านการยืนยันตัวตนแล้ว
- รักษาความสม่ำเสมอในการใช้งาน หลีกเลี่ยงการสร้างแคมเปญจำนวนมากในช่วงสั้น ๆ
- ใช้ progressive spending ค่อย ๆ เพิ่มงบ ไม่อัดทีเดียว
- ตรวจสอบนโยบายล่วงหน้า โดยใช้เครื่องมือ Meta Ads Policy Checker
2. การจัดการเครือข่าย (Network & IP Management)
- ใช้เครือข่ายที่น่าเชื่อถือ เช่น Proxy จาก ISP ไม่ใช่ VPN หรือ datacenter
- ป้องกันการ login หลายบัญชีจาก IP เดียว (หลักการ one IP – one account)
- ตรวจสอบ IP reputation ผ่านเครื่องมือ threat intelligence เช่น AbuseIPDB หรือ Talos
3. การจัดการอุปกรณ์และเบราว์เซอร์ (Device & User-Agent Hygiene)
- ใช้อุปกรณ์สะอาด (Clean Device) ที่ไม่เคยเชื่อมกับบัญชีที่ถูกแบน
- หากจำเป็น ควร reinstall OS ใหม่เพื่อเคลียร์ fingerprint เดิม
- ใช้เบราว์เซอร์มาตรฐาน (Chrome, Edge, Firefox) และไม่ดัดแปลง User-Agent
- แยกสภาพแวดล้อม เช่น ใช้ VM หรือ Antidetect browser เพื่อแยก Profile เฉพาะสำหรับแต่ละบัญชี
4. การจัดการสื่อโฆษณา (Creative & Content Management)
- ผลิตสื่อใหม่ทั้งหมด หลีกเลี่ยงการรีไซเคิลจากแคมเปญที่เคยถูกปฏิเสธ
- ใช้เครื่องมือ third-party เพื่อตรวจหาความคล้ายคลึงของคอนเทนต์ก่อน submit
- ยึดหลักความโปร่งใส: หลีกเลี่ยงข้อความโอเวอร์เคลม, before-after images, และ sensitive keywords
บทสรุป
การระงับโฆษณาบน Facebook Ads ไม่ใช่การสุ่มตรวจ แต่เป็นผลจากกระบวนการ risk-based assessment ที่อาศัยทั้ง machine learning, rule-based detection และ reputation system
ปัจจัยสำคัญ
- Account Reputation: ประวัติการใช้งานและการละเมิด
- Network Fingerprinting: IP และเครือข่าย
- Device Fingerprinting: อุปกรณ์และเบราว์เซอร์
- Content Similarity Detection: ความคล้ายคลึงของสื่อ
แนวทางแก้ไข
- รักษาความสะอาดของบัญชี (Account Hygiene)
- ใช้เครือข่ายที่ปลอดภัย (Network Trustworthiness)
- แยกอุปกรณ์และเบราว์เซอร์ (Device Isolation)
- ผลิตสื่อใหม่ที่สอดคล้องกับนโยบาย (Policy-Compliant Content)
การปฏิบัติตามแนวทางเหล่านี้ไม่เพียงช่วยลดความเสี่ยงในการถูกระงับ แต่ยังช่วยสร้างความน่าเชื่อถือในระยะยาวต่อระบบอัตโนมัติของ Meta
สนับสนุนเว็บไซต์ โดย
ระบบหลบบอทแอด Google Facebook สำหรับสายเทา คลิกเพื่อสั่งซื้อ

Proxy แบบคงที่ คลิกเพื่อสั่งซื้อ
